|
libscid snapshot+b450b7969924
Chess applications made easy.
|
|
libscid snapshot+b450b7969924
Chess applications made easy.
|
Storage codecs are the database layer's persistence adapters. Callers work through scidBaseT; the session owns the resident Index and NameBase, while the active codec knows how to read and write the concrete storage format. That split lets listing, sorting, filtering and metadata queries stay format-agnostic once a database is open.
The public save path starts with Game. The database storage encoder turns it into three pieces: an IndexEntry for compact metadata, TagRoster for the standard PGN names, and a byte buffer containing the encoded game body. The codec then resolves roster names through the name registry, writes or updates the encoded game record, and stores the resulting offsets and name IDs back into the index entry.
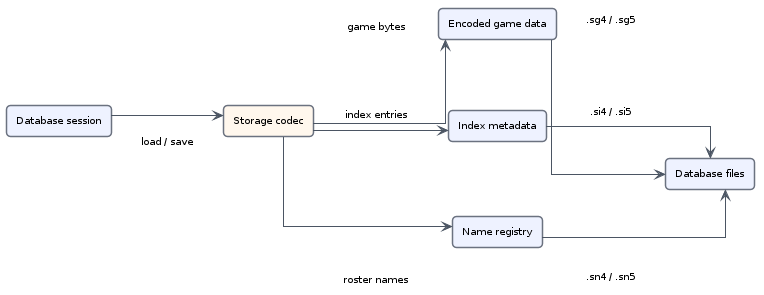
Loading reverses the same boundary. loadGame() reads an IndexEntry, asks the codec for the encoded bytes at the stored offset and length, resolves standard tag strings through TagRoster, and decodes the result into a Game. Move-only and game-view paths use the same encoded record but skip work they do not need.
Native codecs keep the index, namebase and game data in their native form. For SCID5, the file triplet is .si5 for index records, .sg5 for encoded game records and .sn5 for names plus database information. SCID4 follows the older analogous split. Memory storage implements the same codec contract without files, which also gives non-native formats a resident database model to populate.
This diagram shows the storage seam as programmers experience it from the database API. ICodecDatabase and the concrete codec classes are internal implementation types, so the diagram names them conceptually rather than making them part of the public surface. The public values crossing the seam are Game, IndexEntry, TagRoster and encoded bytes.